Accés als indicadors
Per accedir a l’eina HP Diagnostic Server utilitzarem la següent url: https://diagnostics.qualitat.solucions.gencat.cat
Per accedir a l’eina HP Diagnostic Profiler utilitzarem la següent url: http://\<ip sonda\>:35000
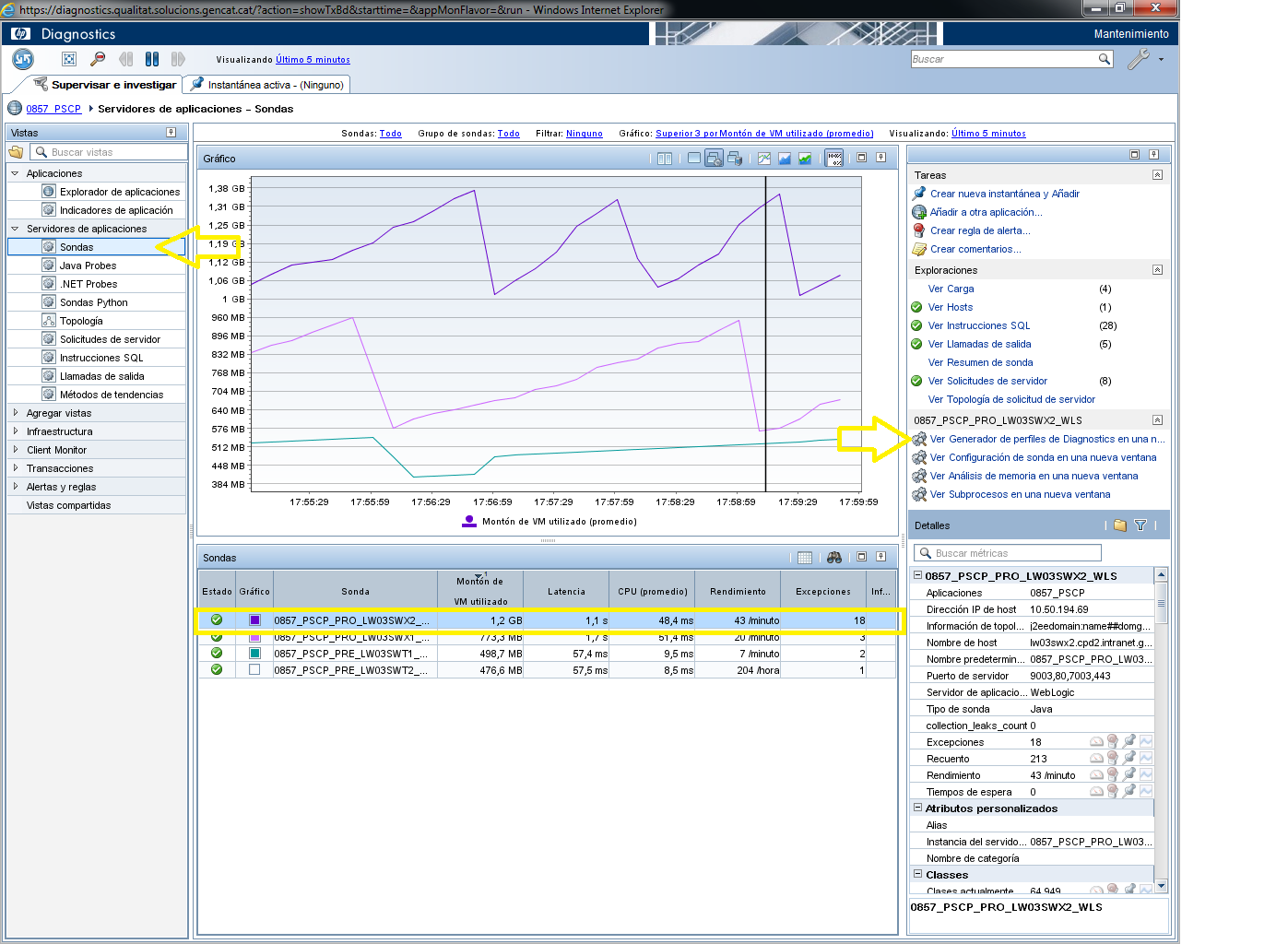
De manera alternativa també es pot accedir a les diferents sondes (HP Diagnostic Profiler) des de l’eina HP Diagnostic Server seguint els passos:
- Accedir al menú “Servidor de aplicaciones” > Sondas > a la secció central dreta (just a sobre de la secció “Detalles”) on hi ha una agrupació de enllaços amb el nom de la sonda seleccionada per defecte a la taula inferior.
- Cal seleccionar la opció “ver generador de perfiles de Diagnostics en una nueva ventana” per a obrir HP Diagnostic Profiles de la sonda seleccionada en una nova finestra.
L’impacte de l´ús de l’eina és molt baix, i no té una afectació rellevant en la disponibilitat o l’eficiència del sistema.

Per consultar la sobrecàrrega estimada de la sonda es pot consultar el següent indicador:
Accedir al menú Vistas > Servidores de aplicaciones > Sondas > Panell “Detalles” > Propietat “Estimación de sobrecarga”.
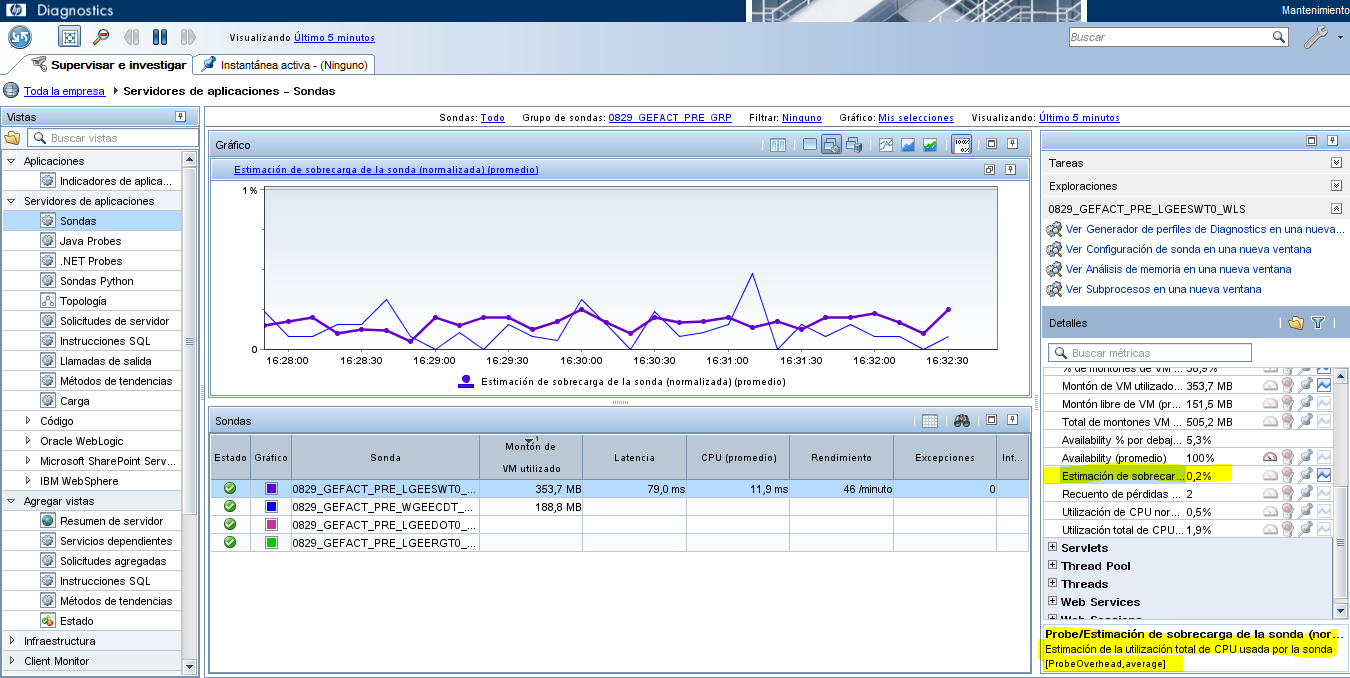
Addicionalment, sempre que es vulgui consultar la gràfica d’un indicador, es pot clicar al botó dret sobre el mateix i seleccionar l’opció “Iniciar gráfico de este indicador”.
Resum dels indicadors
DS: Diagnostics Server, DP: Diagnostics Profiler
| Grup | Indicador | Eina | Com accedir |
|---|---|---|---|
| CPU | CPU | DS i DP |
|
| Memòria | Memòria del sistema | DP | Pestaña Metrics > System > System > Memory Usage > Average.de VM utilizados (promedio) |
| Memòria | Memòria HEAP | DS | Servidores de aplicaciones > Java Probes > Secció “Detalles”, cercar la mètrica “% de montones de VM utilizados (promedio)” |
| Memòria | Garbage collector | DS | Servidores de aplicaciones > Java Probes > Secció “Detalles” cercar l’indicador “Tiempo de GC dedicado a las recopilaciones (promedio)” |
| Memòria | Fugues de memòria (Memory Leaks) | DS | Servidores de aplicaciones > Java Probes > Secció “Sondas” ubicada a la part inferior de la finestra seleccionarem amb el botó dret del ratolí, la sonda que volem inspeccionar i Seleccionar l’opció “Ver Pérdidas de recopilación. Consultarem l’indicador ubicat a la secció ”Detalles” > Collection Leak > Tamaño de la recopilación (promedio). |
| Processos | Threads | DS i DP |
|
| Sol·licituds | Sol·licituds del servidor | DS i DP |
|
| Sol·licituds | Peticions Tomcat | DS | Servidores de aplicaciones > Java Probes > a la secció anomenada “Detalles”, cercar l’indicador “Error Count (promedio)” afegir els gràfics fent botó dret sobre els mateixos i seleccionar l’opció “Iniciar gráfico de este indicador” |
| Accessos BD | Connexions actives JDBC | DS | Servidores de aplicaciones > Java Probes > a la secció “Detalles” cercarem l’indicador “Conexiones activas de JDBC (promedio)”. |
| Accessos BD | Informació SQLs més importants executades | DS | Servidores de aplicaciones > Instrucciones SQL > consultar la Taula ubicada a la part inferior de l’aplicació on es podran revisar els indicadors de les columnes “Latencia” i “Rendimiento |
| Accessos BD | Informació totes SQLs | DP | Sel·leccionar pestanya “Todos los SQL” |
| Eficiència capes | Càrrega capa | DP | Servidor de aplicaciones > Java Probes > a la secció “Detalles” cercarem l’indicador “Carga”. |
| Eficiència capes | Repartiment càrrega/temps per capes | DP |
|
| Excepcions | Excepcions al servidor | DS i DP |
|
| Sessions | Sessions obertes | DS | Servidores de aplicaciones > Java Probes > a la secció “Detalles” cercar l’indicador “Sesiones abiertas/s (promedio)”. |
Avaluació indicadors per detectar més problemes
Respecte al resum previ, s’avaluaran en aquest apartat aquells indicadors més complexos d’analitzar i més importants per detectar on es troba un coll d’ampolla.
Anàlisi de Memory Leaks
Els memory leaks o fugues de memòria acostumen a generar finalment una total indisponibilitat del servidor. Per estudiar si existeixen fugues de memòria podem accedir a l’apartat seguint:
- Servidores de aplicaciones > Java Probes > Secció “Sondas” ubicada a la part inferior de la finestra seleccionarem amb el botó dret del ratolí, la sonda que volem inspeccionar i Seleccionar l’opció “Ver Pérdidas de recopilación.
- Consultar l’indicador ubicat a la secció ”Detalles” > Collection Leak > Tamaño de la recopilación (promedio).
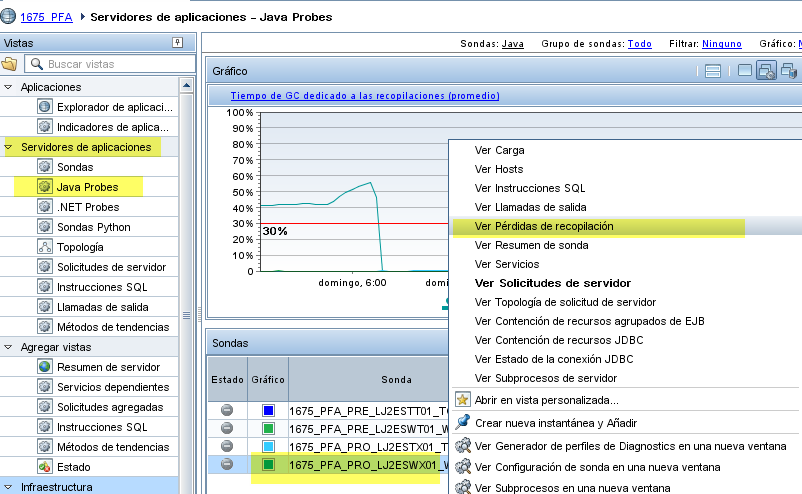
En la part inferior podem veure quines classes són susceptibles de fugues de memòria:
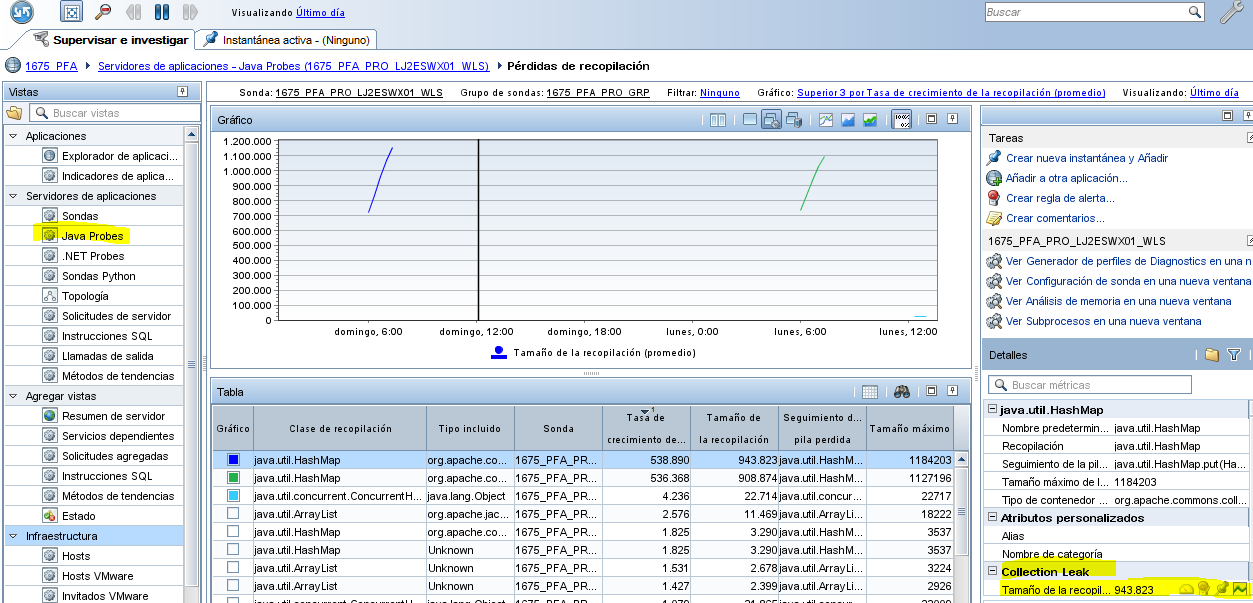
Habitualment veurem que els objectes que generen fugues de memòria son arrays.
Sol·licituds al servidor
En les sol·licituds al servidor podem veure quin temps de resposta total generen diferents peticions.
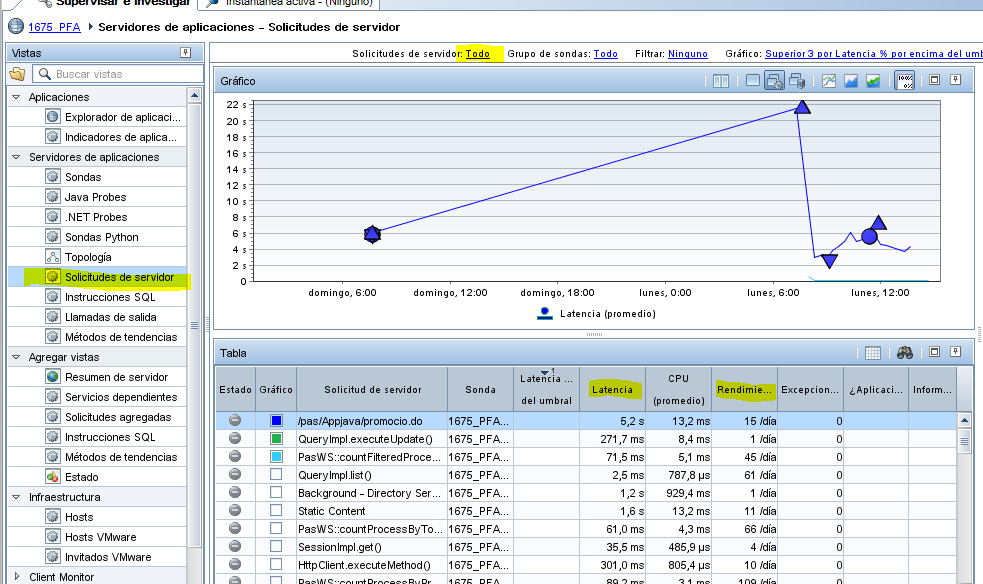
En el cas a dalt mostrat, veiem que la primera url té una latència mitja (temps de resposta) de 5,2 segons, i que s’han fet un total de 15 peticions en 1 dia.
Des del Profiler podem tenir una visió més detallada, per una petició concreta de la latència entre els diferents components que gestionen la petició.
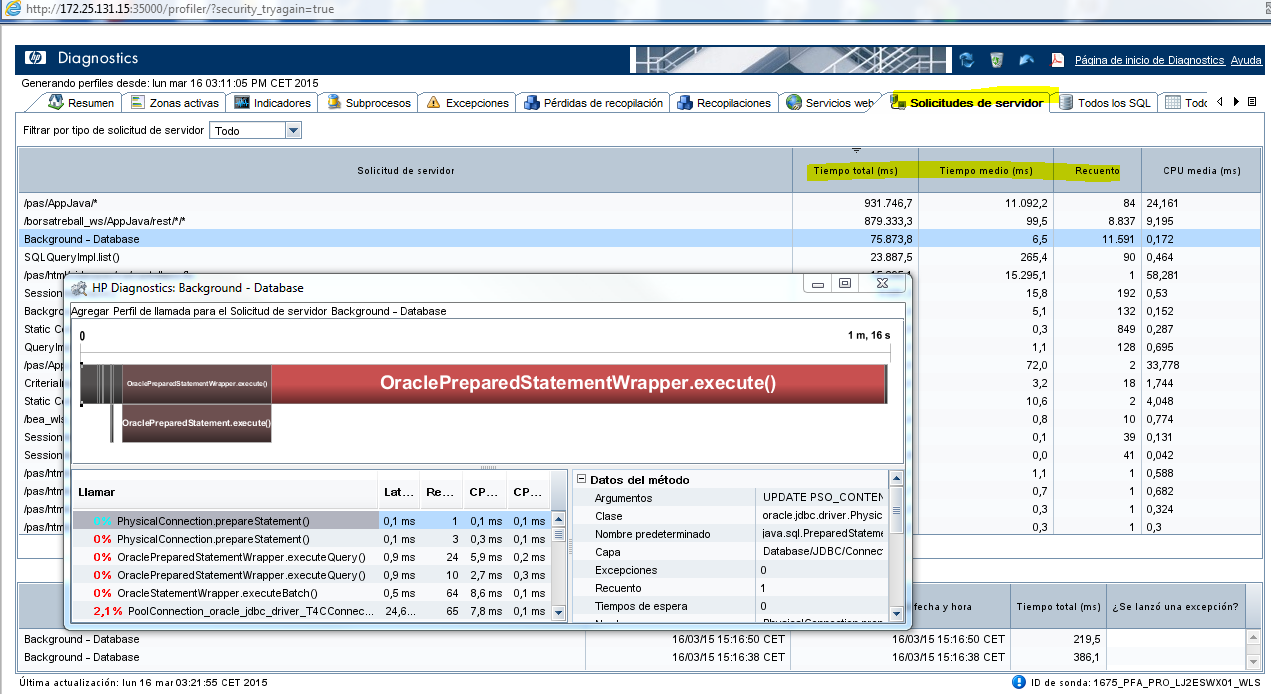
Es poden veure les crides internes al codi per analitzar en quins components està més temps la petició.
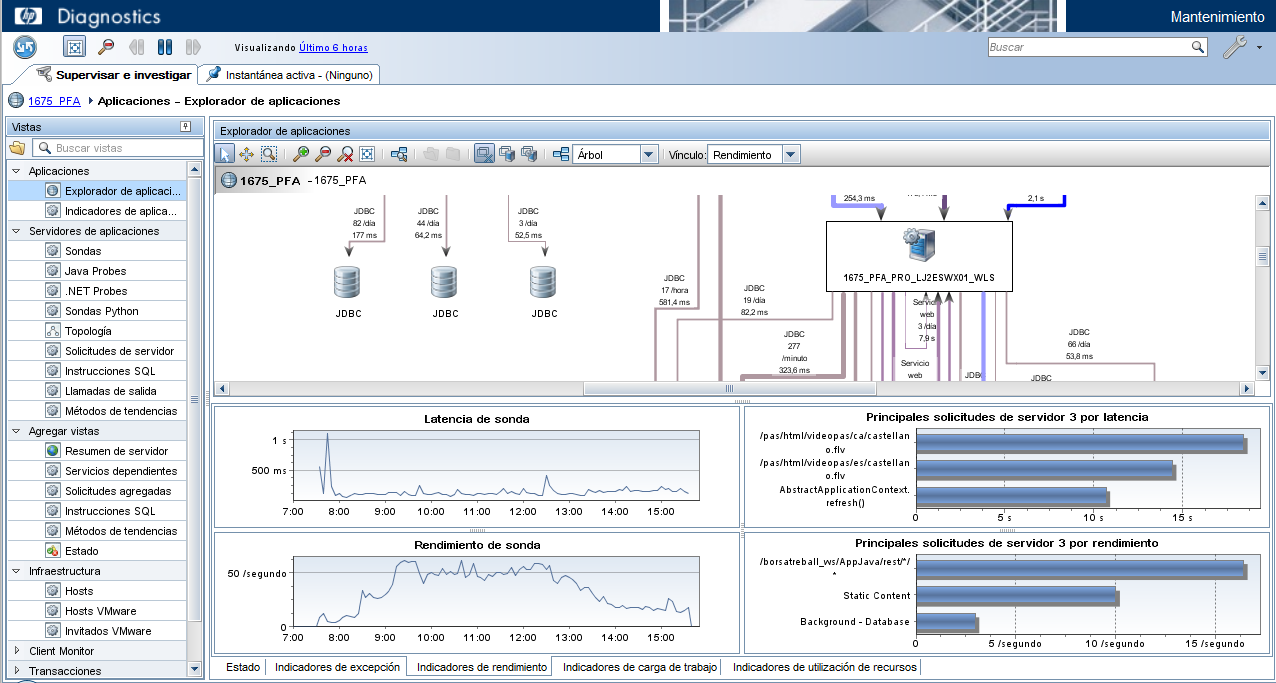
Repartiment del temps en les diferents capes
Una pregunta que s’ha de respondre inicialment és, en quina cap es troba el coll d’ampolla? D’una forma molt visual podem veure el repartiment del temps de resposta en els diferents servidors.
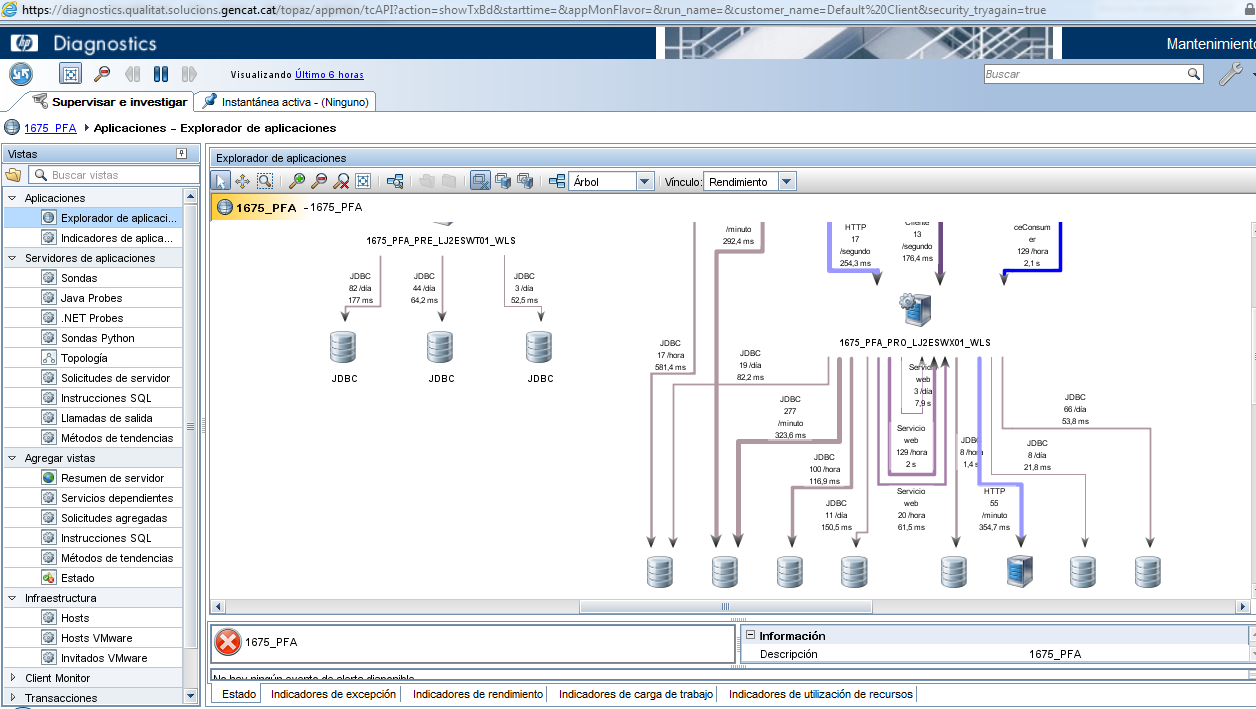
Sessions obertes
Un dels problemés més habituals en les aplicacions Web és la gestió de sessions i el seu tancament.
Accedint a l’opció Servidores de aplicaciones > Java Probes > a la secció “Detalles” cercar l’indicador “Sesiones abiertas/s (promedio)”.
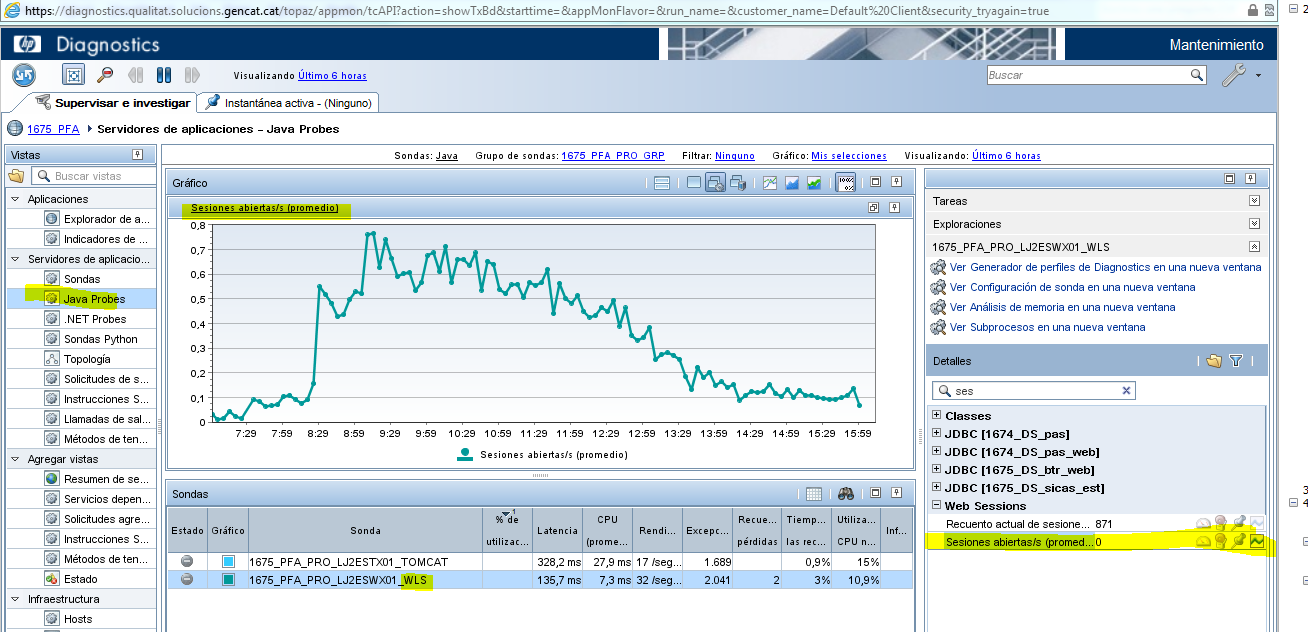
En l’exemple a dalt mostrat es veu clarament com les sessions són alliberades correctament.
Estat dels processos
Per a consultar la informació referent als threads, aquest indicador es pot consultar des del servidor localment. Accedirem a l’eina HP Diagnostic Profiler i seleccionarem la pestanya “Subprocesos”.
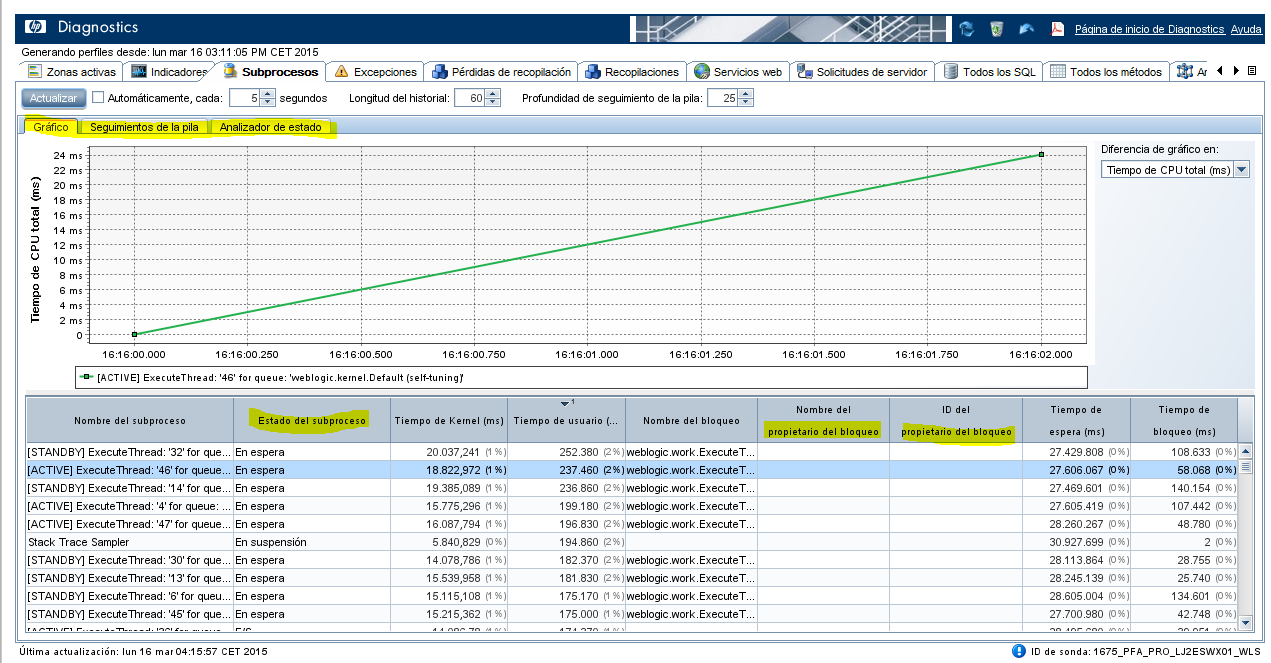
Aquesta vista permet analitzar els processos del servidor, l’estat que tenen en el temps, deadlocks, instruccions que realitzen en el temps i el seu comportament.
Es pot consultar l’estat dels processos/subprocessos seleccionant la pestanya “Analizador de estado” o “State Analyzer”.
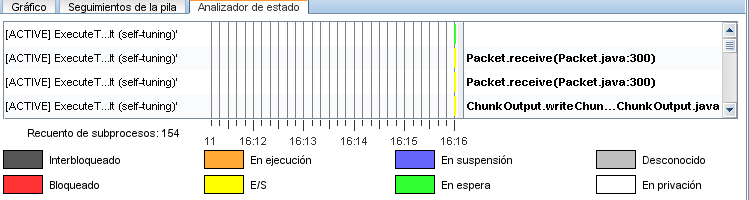
A continuació es llisten els estats més significatius dels threads del Diagnostic Profiler:
- Running - Ejecutando
- Blocked – Bloqueado
- Starving – En privación (Inanición)
- Waiting – En suspensión
- Deadlocked – Interbloqueado
En l’estat de Blocked, un fil està a punt d’entrar en un bloc synchronized, però hi ha un altre fil que s’executa dins d’un bloc synchronized en el mateix objecte. El primer fil ha d’esperar que el segon fil surti del seu bloc.
En l’estat Waiting, un fil està esperant un senyal d’un altre fil. Això succeeix normalment cridant Object.wait (), o Thread.join (). El fil llavors romandrà en aquest estat fins que un altre subprocés cridi Object.notify (), o mori.
En l’estat de Starving, a un fil se li denega sempre l’accés a un recurs compartit. Sense aquest recurs, la tasca a executar no pot ser mai finalitzada.
La Starving és una situació similar a Deadlocked, però les causes són diferents. En el Deadlocked dos processos o dos fils d’execució arriben a un punt mort quan cadascun d’ells necessita un recurs que és ocupat per l’altre. En canvi, en aquest cas, un o més processos estan esperant recursos ocupats per altres processos que no es troben necessàriament en cap punt mort.
La utilització de prioritats en molts sistemes operatius multitasca podria causar que processos d’alta prioritat s’estiguessin executant sempre i no permetessin l’execució de processos de baixa prioritat, causant Starving en aquests. És més, si un procés d’alta prioritat està pendent del resultat d’un procés de baixa prioritat que no s’executa mai, llavors aquest procés d’alta prioritat també experimenta Starving (aquesta situació es coneix com a inversió de prioritat). Per evitar aquestes situacions els planificadors moderns incorporen algorismes per assegurar que tots els processos reben un mínim de temps de CPU per executar-se.
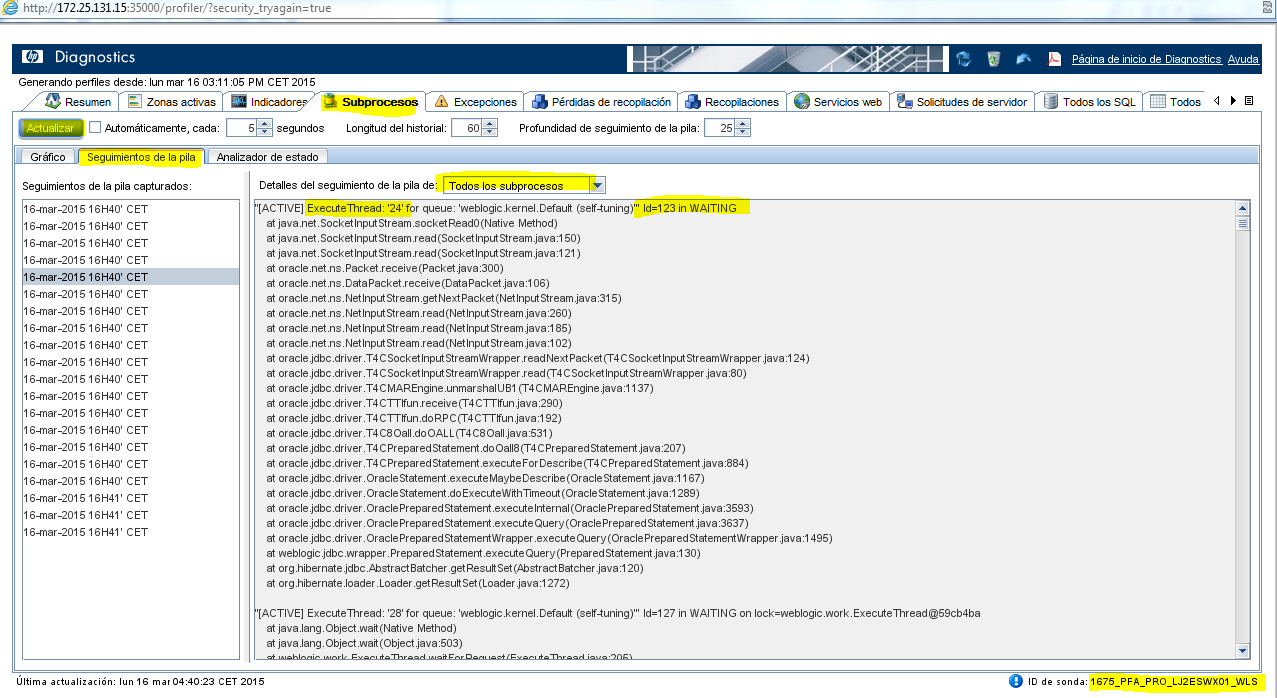
Tanmateix es pot consultar la pila dels processos accedint a la pestanya “Seguimientos de la pila” seleccionar la pestanya continguda en aquesta secció amb el nom “Seguimientos de la pila”.